
The commonly stated objectives behind regulating the content generative AI can serve imply the implementation is usually via human opinions. This is challenging task since the opinions and resulting censoring of AI generated content needs to somehow fit all possible purposes a user can have, different personalities and needs of the users, and as highlighted in our earlier article great danger of obstructing useful outliers. In other words, the principle of outliers can be extended to not only all content but even a user may be an outlier w.r.t. the general population or find themselves in the outlying situation where the outlying content was the most optimal one to serve for whatever target objective the user had.
As illustrated on the top of Figure 1, different kind of regulations are already in place in the whole information cycle, such as public visibility, content policies and sources of AI training data. Besides being unnecessary, it is very risky to add any regulation at the AI engine level that has only made all this data interactable with. It could also be a trigger for ongoing contraction of the diversity of knowledge and creations within the flow of the cycle. Knowledge/discovery optimisation wise it would be analogous to being stuck in local optima. Global optima may never be confirmable, as we have always discovered new ways to accomplish goals better. There were periods in history and a likelihood now, that we are wastefully satisfying some human needs, given that at the time dominant beliefs or funding bodies only encouraged the progress within a suboptimal paradigm.
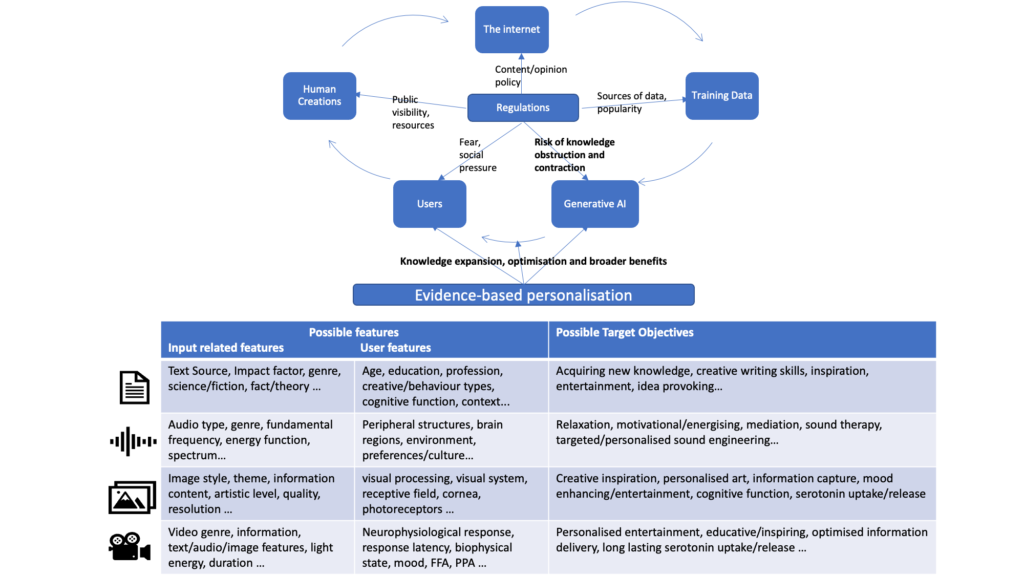
Figure 1: The overregulated information age: risk and optimisation opportunities
While we strive to make AI accessible to all to empower their cognitive and creative tasks, the AI itself does not need to take on a personality and therefore, have its responses heavily judged by the community, as we saw recently with ChatGPT. The Large Transformer Models behind the generative AI have captured most of the human knowledge and hence can mimic any artefact of it. We need not to assign it a hyped sci-fi personality as that has easily propagated false fear in the past. The Large Language Transformer Model (LLTM) is much closer to a textual world simulation in its raw form and users should be able to choose any interaction type (chat, scenario outplay) or persona it likes whether an AI system, a human expert or anything AI can impersonate (this is what motivated the way Lateral AI app serves a LLTM to its users). Besides customisation options by which users control how generative AI is served to them, AI can empower users even further having learned ‘sufficient’ example pairs between human creations and target objectives (moods, emotions, bodily/psychological benefit etc.)
On the bottom of Figure 1, for each type of creation (artificial or human) we list some examples of input and user related features, that one could try to capture as context or tweakable parameters to serve content in line with personal target objectives set by the user. There is a strong overlap across the features and target objectives especially as video can cover other inputs and related effects on the user or their target objectives. Example implementations once sufficient training examples are available could be: (1) a pretrained optimiser that feeds into the generative AI the optimal settings for the tweakable content features for the given user context and target objective and (2) retraining of large transformer models to include mappings between content, user context and target objectives.
The first approach can offer an immediate evidence-based content serving for measured user context and target objectives as an instruction to existing pretrained models. However, the limits are that mainly individual target objectives can be tailored to at a time and competing objectives are not taken into the account. In other words, we could get stuck in a local optimum as to reach a global optimum all related information needs to be accounted for. Thus, a greater opportunity lies the second option as besides accounting for all information by the generative model itself tweakable parameters for the creation will be automatically discovered and set. At even a more generalised level, model could take as input a target objective directly and serve the most personalised content whether it be text, audio or video, optimised for that target objective. Nevertheless, the mechanism implemented needs to allow for open ended context features and target objectives for the emerging state and needs of the users, respectively.
As we see to allow unbiased evidence-based ‘regulation’ (or rather optimisation) of generative AI is not an easy task. The current direction of opinion based human regulation lacks in diversity of both features of content and user target objectives. It is therefore no surprise that we see state-of-the-art conversational systems ‘fail’ in eyes of some or on some cases. Some users managed to push it to undesired response angles despite regulations put in place. One cannot however call this an AI failure; it is just an imperfection of impersonating a chatbot most people desired while it can also be seen as an actual success of AI in impersonating that far when provoked. It knew what sentient AI would sound to people or how it triggered its acceptance or fear in sci-fi movies and there is randomness in which response it will choose. Hence, the actual error or misdirected hype, is that of trying to serve AI as an all facts knowing and user satisfying conversational agent. This provokes both excitement and fear in people given the alignment to AI sci-fi movies exposed to. This direction calls for premature regulations that lack evidence and directly or indirectly discriminate against some human creations and user target objectives. We believe more benefits lie in serving the generative AI as an engine for people to co-create with and encourage the creator/scientist mindset instead of that of others’ regulated knowledge/creations consumer. Hence the importance of preserving the totality of the human knowledge and creations in these AI engines or else there is a risk we may be programming the humans into a deeper state of suboptimal being.